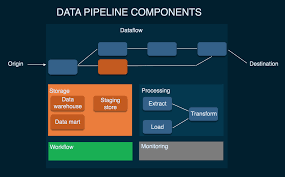
Data pipelines are a fundamental component of modern data architecture. They facilitate the movement and transformation of data from various sources to target systems, enabling data integration, analysis, and processing. A data pipeline is a series of steps and processes that extract data from its source, perform necessary transformations, and load it into a destination system. Here’s an introduction to data pipeline concepts and architectures:
- Data Sources:
Data pipelines start with the identification and connection to various data sources. These sources can include databases, data warehouses, streaming platforms, applications, APIs, log files, or external data providers. Each source may have different formats, structures, and protocols for data access. - Data Extraction:
The data extraction step involves retrieving data from the identified sources. This can be done through methods such as querying databases, pulling data from APIs, ingesting streaming data, or reading files. Extraction methods may vary based on the source and its capabilities. - Data Transformation:
Once the data is extracted, it often requires transformation to make it suitable for downstream processing and analysis. Data transformation involves cleaning, filtering, aggregating, enriching, or reshaping the data to meet specific requirements. Common transformation techniques include data normalization, joining, splitting, data type conversions, and applying business rules. - Data Quality and Validation:
Data quality and validation steps ensure that the data is accurate, complete, consistent, and conforms to defined standards. This may involve performing data profiling, identifying and handling missing or erroneous data, implementing data validation rules, and applying data quality checks. - Data Processing and Enrichment:
In some cases, data pipelines involve more advanced processing or enrichment steps. This can include applying machine learning algorithms, natural language processing, feature engineering, or data enrichment through external data sources. These steps add value to the data and enhance its usability for downstream applications. - Data Loading:
After the necessary transformations and processing, the transformed data is loaded into the target systems. This could be a data warehouse, data lake, analytical database, or any other system that serves as the central repository for the data. Loading can be done through batch processing or real-time streaming, depending on the requirements and latency considerations. - Workflow Orchestration:
Data pipelines often involve complex workflows with multiple steps and dependencies. Workflow orchestration manages the sequencing, scheduling, and coordination of these steps to ensure proper execution. It handles job dependencies, parallel processing, error handling, retries, and monitoring of pipeline activities. Popular workflow orchestration tools include Apache Airflow, Apache NiFi, and Luigi. - Data Governance and Security:
Data pipelines should adhere to data governance policies and ensure data security and privacy. Implement access controls, encryption, anonymization, and masking techniques to protect sensitive data. Ensure compliance with relevant regulations such as GDPR or CCPA and establish data lineage and auditing capabilities. - Monitoring and Error Handling:
Monitoring is crucial for data pipelines to ensure their smooth operation. Implement monitoring mechanisms to track pipeline performance, data quality, job statuses, and data flow. Set up alerts and notifications for errors, failures, or delays. Implement error handling and retry mechanisms to handle transient failures or exceptions. - Scalability and Resilience:
Design data pipelines to be scalable and resilient to handle increasing data volumes and accommodate future growth. Utilize distributed computing technologies, parallel processing, and cloud-based infrastructure to scale pipelines horizontally. Implement fault-tolerant mechanisms, such as redundant pipelines or data replication, to ensure high availability and data integrity.
Data pipeline architectures can vary based on the specific needs and technologies used. Common architectures include batch processing pipelines, real-time streaming pipelines, event-driven architectures, and hybrid approaches that combine batch and real-time processing. The choice of architecture depends on factors like data freshness requirements, latency constraints, processing complexity, and cost considerations.
Designing and implementing effective data pipelines requires careful planning, consideration of data flow, transformations, and integration requirements. It’s important to understand the characteristics of data sources, the processing capabilities of the target systems, and the overall objectives of the data pipeline to design a robust and scalable architecture.