Designing and implementing a relational database involves several steps to ensure that the database structure is efficient, scalable, and meets the requirements of the application or system. Here’s an overview of the process:
- Requirements Gathering:
The first step is to gather requirements from stakeholders and understand the purpose and scope of the database. Identify the entities, relationships, and attributes that need to be stored and managed in the database. Determine the functional and non-functional requirements, data volume, expected usage patterns, and performance requirements. - Conceptual Data Modeling:
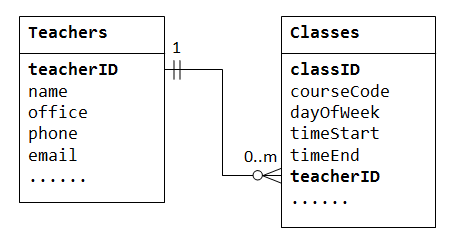
Using the gathered requirements, create a conceptual data model that represents the high-level structure and relationships of the database. This can be done using techniques like entity-relationship diagrams (ER diagrams). The conceptual model helps in visualizing the entities, relationships, and attributes and provides a foundation for the database design. - Normalization:
Normalization is the process of organizing data to minimize redundancy and dependency issues. Apply normalization techniques, such as the normal forms (e.g., first normal form, second normal form, etc.), to eliminate data duplication and ensure data integrity. Normalization helps in optimizing storage space and improving data consistency. - Logical Data Modeling:
Based on the conceptual data model, create a logical data model that translates the conceptual design into a database schema. Use a database modeling language like SQL (Structured Query Language) to define tables, columns, primary and foreign keys, and constraints. The logical model defines the database structure at a detailed level and serves as the blueprint for the physical implementation. - Physical Data Modeling:
In the physical data modeling phase, translate the logical data model into a specific database management system (DBMS) implementation. Consider the specific features, capabilities, and constraints of the chosen DBMS. Define data types, indexing strategies, partitioning schemes, and other performance optimization techniques. The physical data model focuses on the efficient storage and retrieval of data. - Database Schema Creation:
Using the physical data model, create the database schema by executing SQL statements or using database management tools. This involves creating tables, defining columns, specifying primary and foreign keys, setting up constraints, and establishing relationships between tables. The schema creation process establishes the structure of the database and prepares it for data insertion and manipulation. - Data Population:
Once the database schema is in place, populate the tables with data. This can be done manually or through automated processes like data migration or data import tools. Ensure data consistency and integrity during the population process and consider any data transformation or cleansing requirements. - Indexing and Performance Optimization:
Analyze the usage patterns and performance requirements of the database and create appropriate indexes to improve query performance. Consider factors like data access patterns, joins, filtering conditions, and sorting requirements. Test and optimize the database performance by monitoring query execution, indexing strategies, and database configuration parameters. - Security and Access Control:
Implement security measures to protect the database and its data. Define user roles and access privileges, enforce authentication and authorization mechanisms, and apply encryption and data masking techniques as necessary. Ensure that sensitive data is appropriately protected and comply with relevant security standards and regulations. - Ongoing Maintenance and Monitoring:
Regularly monitor the database for performance, data consistency, and integrity. Perform routine maintenance tasks like backups, database optimization, and data archiving. Address any issues or bottlenecks that arise and continuously refine the database design based on evolving requirements and performance analysis.
Designing and implementing a relational database requires careful planning, consideration of requirements, and adherence to best practices. By following these steps, you can create a well-structured and efficient database that effectively stores and manages your data.
SHARE