23
Sep
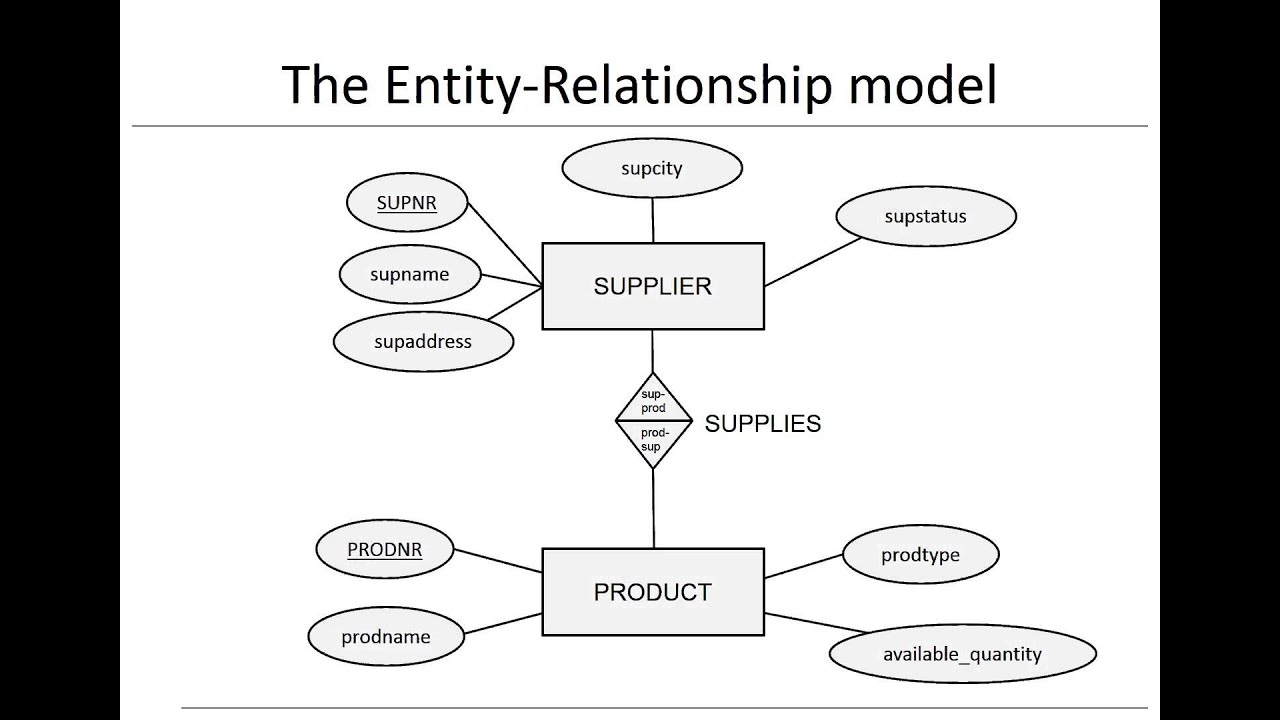
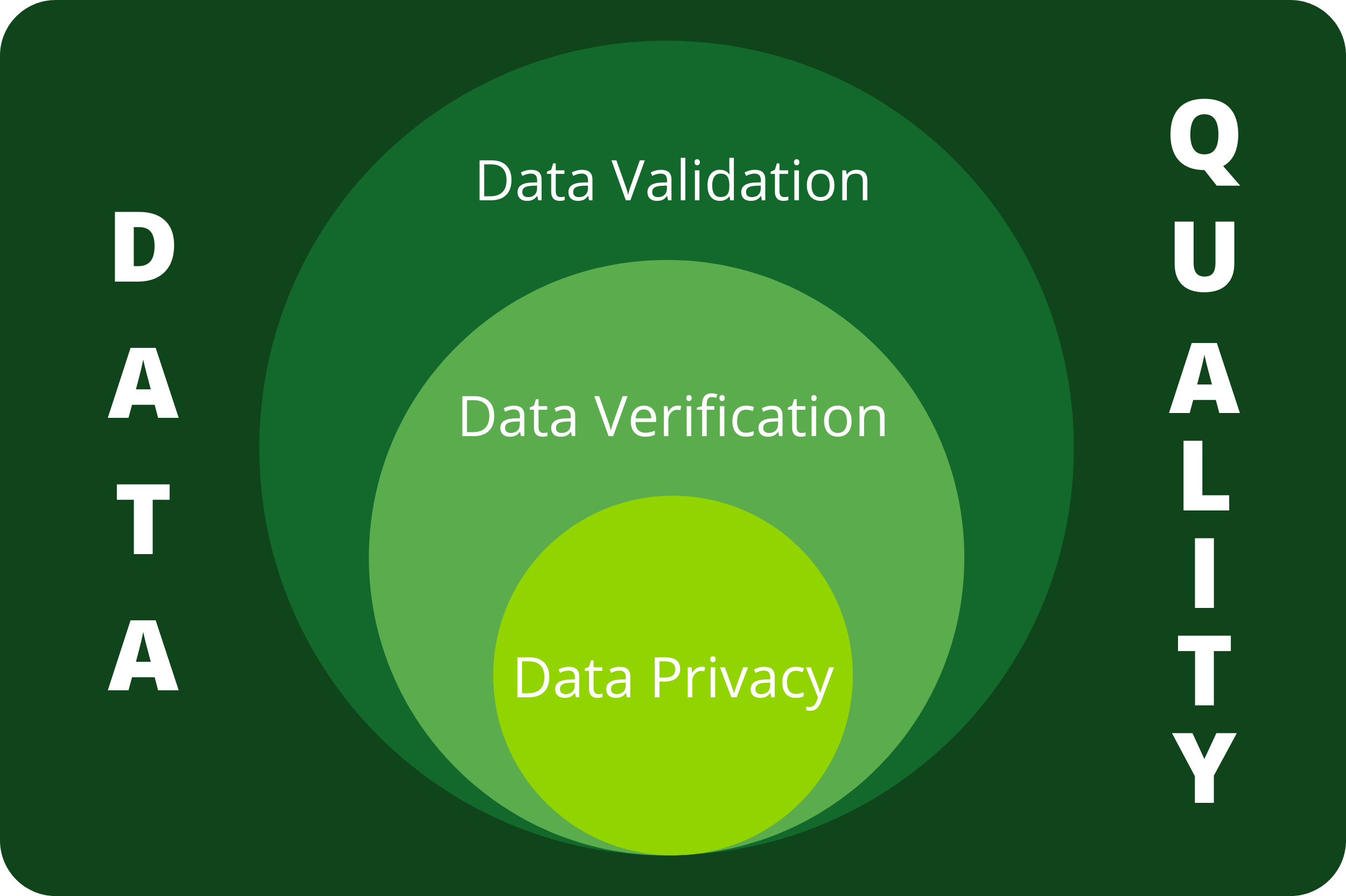
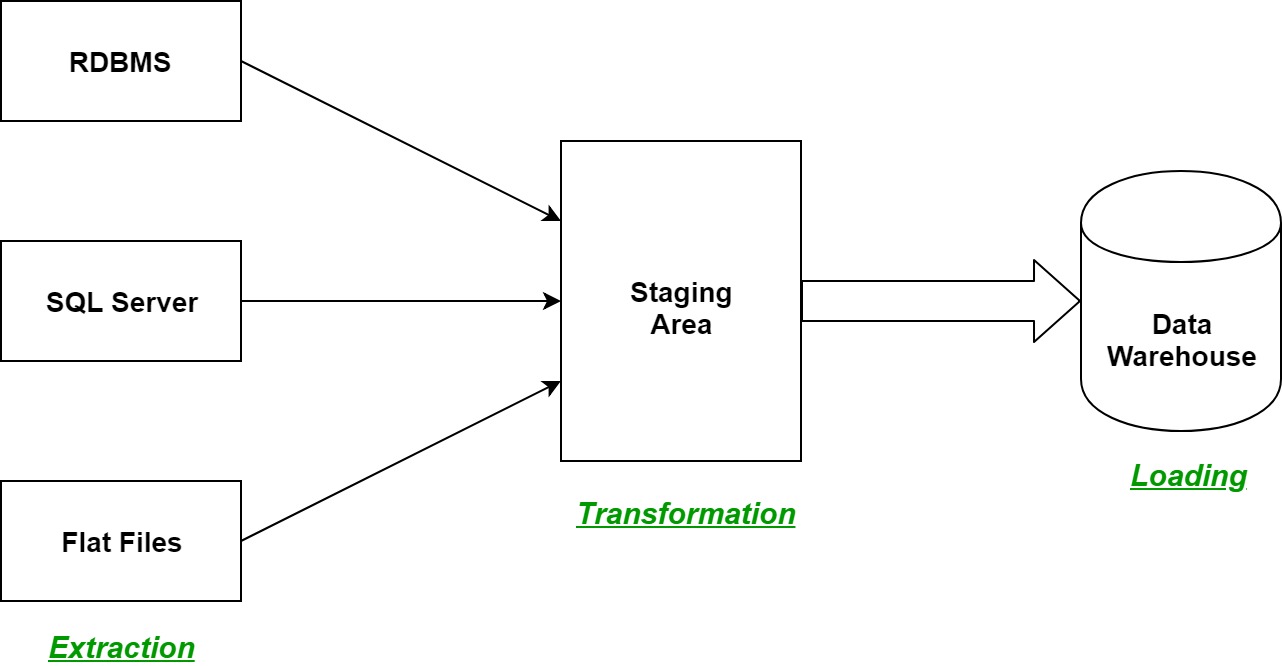
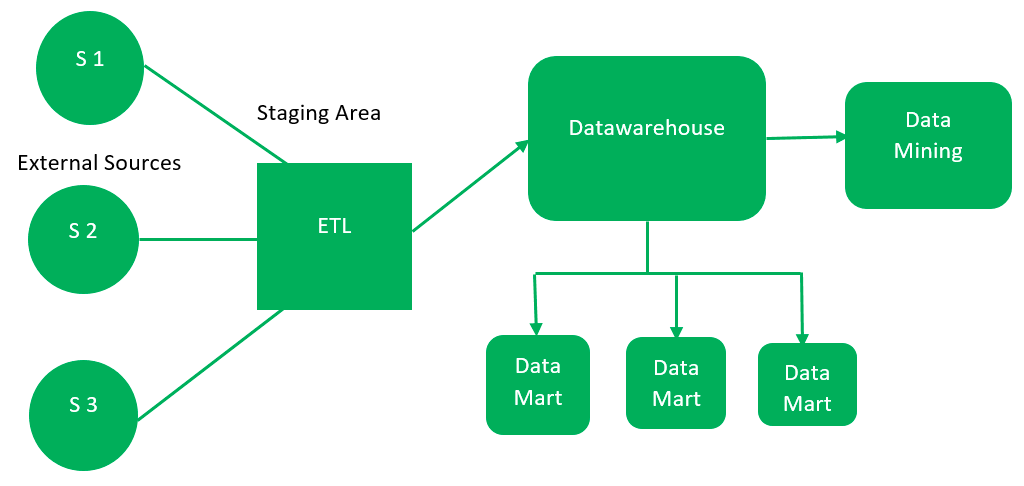
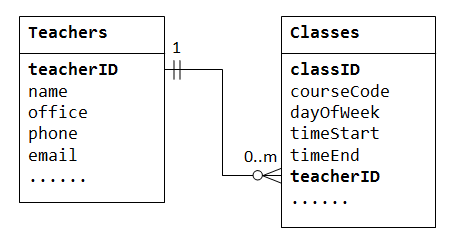
Designing and implementing a relational database involves several steps to ensure that the database structure is efficient, scalable, and meets the requirements of the application or system. Here's an overview of the process: Requirements Gathering:The first step is to gather requirements from stakeholders and understand the purpose and scope of the database. Identify the entities, relationships, and attributes that need to be stored and managed in the database. Determine the functional and non-functional requirements, data volume, expected usage patterns, and performance requirements. Conceptual Data Modeling:Using the gathered requirements, create a conceptual data model that represents the high-level structure and relationships…